Non non, je ne mange pas de la purée de fichier tous les matins ! Le hachage des fichiers permet d'avoir une empreinte permettant de vérifier l'intégrité du fichier, par exemple pour vérifier si un téléchargement c'est bien passé. Il est aussi très utilisé pour éviter de mettre les mots de passe en clair quelque part.
Pour les mots de passe le problème de vitesse ne ce pose pas trop car les codes sont très courts (de 8 à 32 octets en général) mais pour les fichiers la vitesse peut être un critère si on gère de gros volumes ou que l'on est sur un serveur mutualisé. Il existe différentes méthodes pour hasher un fichier ici on teste :
- La somme (sum), dans la pratique vivement déconseillé
- Le crc (cksum), un peu mieux mais pas top
- md5 (md5sum)
- divers algorithmes sha (sha1 sur 160 bits, et les versions 224, 256 et 512 bits), le sha512 est le plus sûr de tous ceux qui sont testés
Les tests ont été faits sur un iso de la distribution Linux Debian qui fait 158,9 Mo. Les temps d'accès au disque ne comptent pas, on suppose qu'il est toujours en mémoire cache. Pour un disque dur moyen (50 Mo/s) il faudrait ajouter a peu près 3,2s.
Les tests mesurent le temps d'exécution réel des commandes Linux indiquées. Pour plus de précision on teste 5 fois et on extrait la valeur médiane :
sum : 0,563s cksum : 0,703s md5sum : 0,524s sha1sum : 0,892s sha224sum : 1,577s sha256sum : 1,572s sha512sum : 1,085s
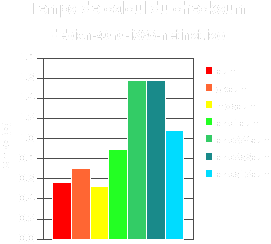
On remarque que c'est le md5sum qui est le plus rapide, encore plus que le "sum" et "cksum". Pour les SHA on évitera les versions 224 et 256 bits, trop lentes et utilisera les versions 160bits ou 512bits.